Email Address Deduplication: Methods and Best Practices
Somewhere in your CRM right now, the same person exists as three different contacts. Maybe their email appears once from a webinar registration, once from a content download, and once from a sales rep manually entering it. Each record has slightly different data. And when you send a campaign, that person gets the same email three times.
This is not a hypothetical scenario. Average CRM databases contain 10-30% duplicate records. That means if you have 50,000 contacts, somewhere between 5,000 and 15,000 of them are duplicates. You are paying to store them, paying to email them, and annoying the recipients who receive multiple copies.
Deduplication sounds simple: find the copies and merge them. In practice, it gets complicated fast. This guide covers the technical methods, edge cases, and practical approaches to getting your database clean.
Why Duplicates Happen
Understanding how duplicates enter your database helps you prevent them in the future.
Multiple entry points. A prospect fills out a whitepaper form, then a webinar registration, then a demo request. If your systems do not check for existing records, each submission creates a new contact.
CRM imports. Bulk importing a CSV of leads from a conference, a purchased list, or a sales tool without checking against existing contacts is one of the biggest duplicate generators.
Manual entry by sales reps. A rep meets someone at an event and adds them to the CRM without searching for an existing record. The same person now exists twice with slightly different data.
System integrations. Marketing automation syncing to CRM, or CRM syncing to an outreach tool. If the sync logic does not properly match existing records, it creates new ones.
Form resubmissions. The same person fills out a form again with a slightly different email (personal vs work, or a new company email after a job change). Both are valid but they are the same person.
Types of Duplicates
Not all duplicates are created equal. Each type requires a different detection approach.
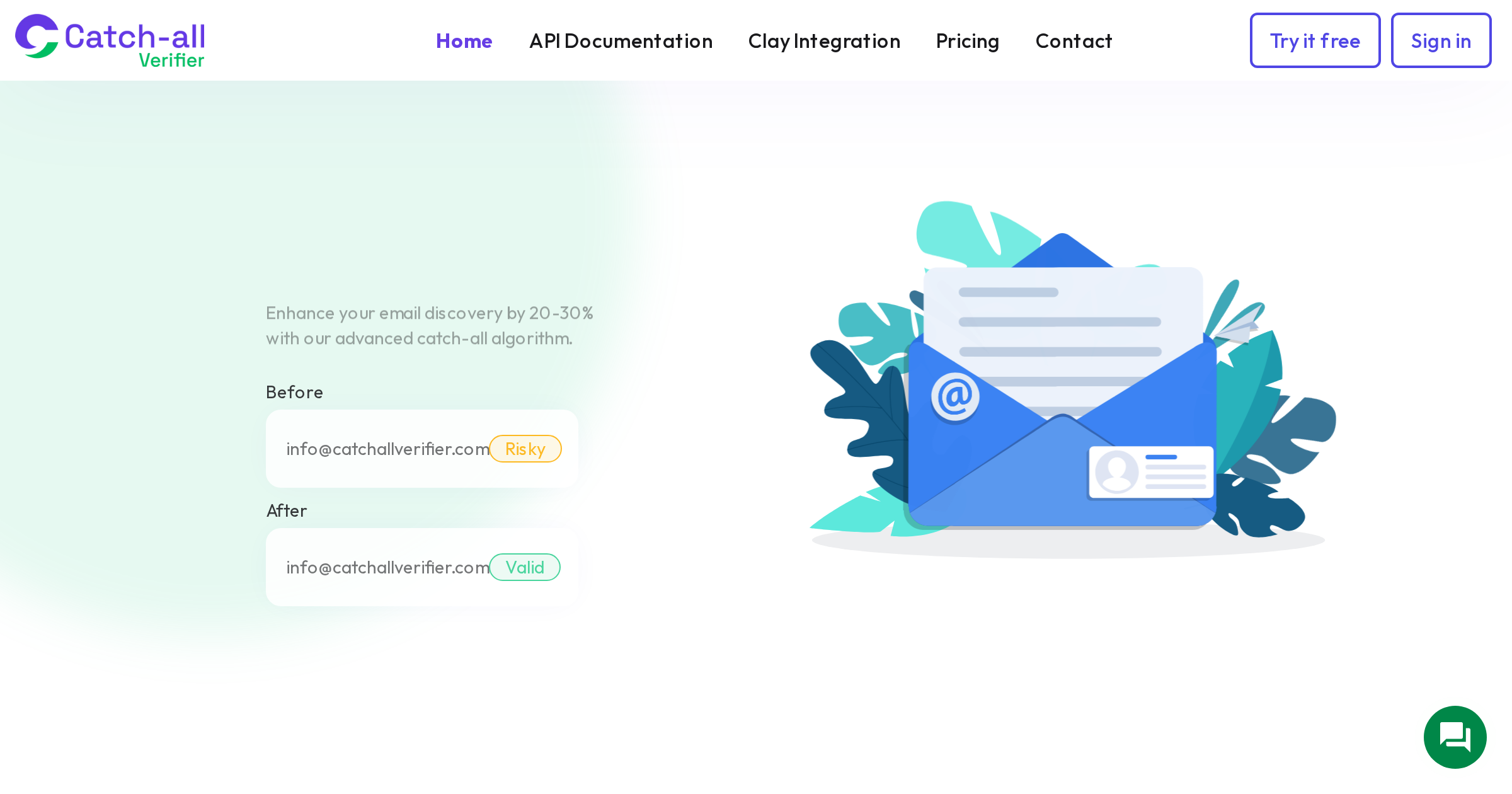
Exact email matches. The simplest case: the same email address appears multiple times. Detection is straightforward. Case-insensitive comparison (email addresses are functionally case-insensitive) catches these immediately.
Format variations. The same underlying address in different formats: john.smith@gmail.com vs johnsmith@gmail.com. Gmail specifically ignores dots in the local part, so these deliver to the same inbox. Similarly, john+newsletter@gmail.com and john+webinar@gmail.com are the same person (Gmail ignores everything after the + sign).
Domain aliases. Some organizations have multiple domains that route to the same mailboxes. @company.com and @company.co.uk might both be valid for the same person. This is harder to detect automatically.
Cross-email duplicates. The same person with different email addresses: john@company.com (work) and john.smith@gmail.com (personal). Matching these requires additional data points like name, phone number, or company affiliation.
Detection Methods
Exact match deduplication. The simplest approach: compare email addresses directly. Normalize them first by converting to lowercase and trimming whitespace. This catches exact duplicates but misses format variations.
Gmail normalization. For Gmail addresses specifically, strip dots from the local part and remove everything after a + sign before comparing. john.smith+work@gmail.com becomes johnsmith@gmail.com. Apply the same logic to googlemail.com addresses, which are aliases for gmail.com.
Domain normalization. Some domains are equivalent. googlemail.com and gmail.com are the same. Check for known domain aliases in your deduplication logic.
Fuzzy matching. For catching near-duplicates (john@company.com vs john@compnay.com), use fuzzy string matching algorithms like Levenshtein distance. Set a similarity threshold (like 90%) to flag potential duplicates for manual review. Be careful with this: set the threshold too low and you will get false positives. Two different people named John at similar but different companies are not duplicates.
Multi-field matching. To catch cross-email duplicates (same person, different addresses), match on combinations of other fields: first name + last name + company, phone number, LinkedIn URL, or mailing address. This requires more data but catches duplicates that email-only matching misses.
Merge Strategies
Once you identify duplicates, you need to decide how to merge them. The key decisions are which record becomes the primary (the one that survives) and how to handle conflicting data.
Most recent wins. The most recently updated record becomes primary, and its data takes precedence for conflicting fields. This works well when you trust your latest data more than older data.
Most complete wins. The record with the most filled-in fields becomes primary. Empty fields in the primary are filled with data from the duplicate. This maximizes data completeness.
Source priority. Assign priority to data sources. A record from your CRM might take precedence over one from a webinar registration, which takes precedence over a purchased list import. Conflicting fields are resolved based on source priority.
Manual review for high-value contacts. For contacts associated with open deals, high engagement history, or significant account value, do not auto-merge. Flag them for manual review so a human can make the right call on conflicting data.
Regardless of strategy, always preserve the merge history. Keep a record of which records were merged, when, and what data was from each source. This lets you undo bad merges and audit your data quality over time.
Preventing Future Duplicates
Deduplication is a reactive fix. Prevention is better.
Check before creating. Configure your CRM and form integrations to search for existing contacts before creating new ones. Match on email address (normalized), and optionally on name + company as a secondary match. If a match is found, update the existing record instead of creating a new one.
Standardize data entry. Create clear guidelines for how contacts should be entered. Define required fields, formatting standards (e.g., always lowercase email), and the process for checking existing records before manual entry.
Audit imports before processing. Before importing a CSV into your CRM, run a deduplication check against both the import file (for internal duplicates) and your existing database (for cross-system duplicates). This is a five-minute step that prevents hours of cleanup.
Set up CRM duplicate detection rules. Most CRMs (Salesforce, HubSpot, Pipedrive) have built-in duplicate detection that you can configure. These rules fire when new records are created and alert you to potential duplicates. Turn them on and configure them to match your deduplication criteria.
Tools for Deduplication
For small databases, manual deduplication in a spreadsheet works. Sort by email, scan for duplicates, merge manually. For anything over a few thousand contacts, you need tooling.
CRM built-in tools. Salesforce has duplicate management rules and the DupeCatcher app. HubSpot has a built-in duplicate management tool that identifies and merges duplicates. Most major CRMs offer some form of duplicate detection.
Dedicated deduplication tools. Services like Dedupely, DemandTools (for Salesforce), and Insycle specialize in finding and merging duplicates across your database. They support fuzzy matching, custom merge rules, and bulk operations.
Spreadsheet methods. For one-time cleanups, export your database to CSV, use Excel or Google Sheets to identify duplicates (COUNTIF, conditional formatting, pivot tables), resolve them, and reimport. Not elegant, but it works.
Custom scripts. If you have developer resources, a Python script with pandas can perform sophisticated deduplication with custom matching logic. This is useful when your deduplication needs do not fit neatly into off-the-shelf tools.
Deduplication and Email Verification
Deduplication and email verification are complementary processes that should happen together.
Run deduplication first. There is no point verifying the same email three times because it exists as three separate records. Deduplicate, then verify the surviving records. This saves verification credits and gives you clean, verified, unique contacts.
When you encounter catch-all domains during verification, the deduplication context can help. If you have two records for the same person at a catch-all domain (maybe from different data sources), merging them first means you only need one catch-all verification credit through CatchallVerifier instead of two.
Build deduplication into your regular data maintenance schedule. Run it quarterly alongside re-verification. Your database is a living system that accumulates duplicates continuously. One-time cleanup is not enough; you need an ongoing practice.
The result is a database where every record is unique, verified, and actionable. No wasted send credits on duplicates, no annoyed recipients getting multiple copies, and no inflated contact counts giving you a false sense of your actual audience size.